Documentation index: llms.txt. This page is also available as markdown: append .md to this URL or send Accept: text/markdown.
Node Type V2
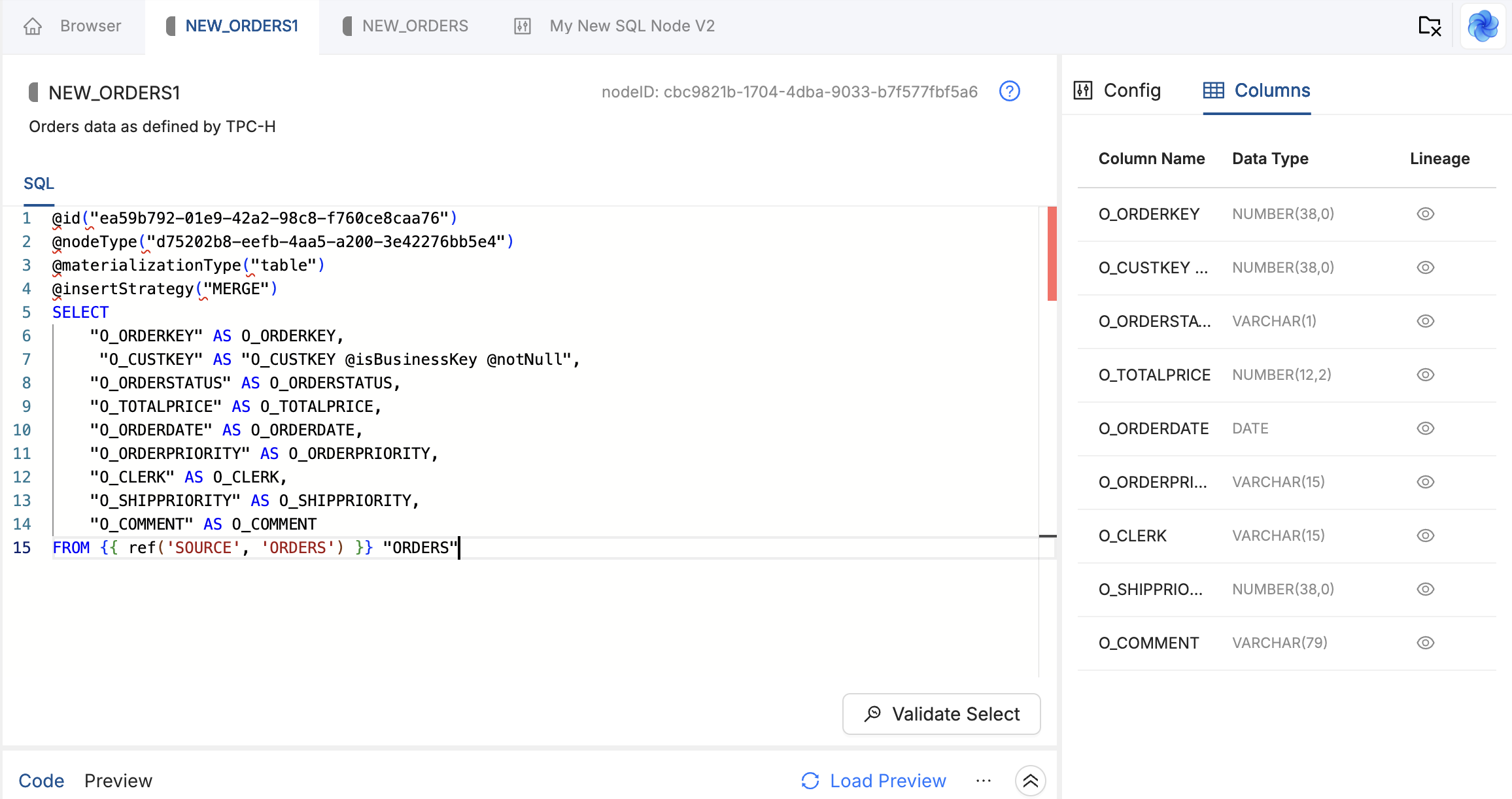
Node Type V2 is a SQL-first authoring experience. You write a SQL SELECT in the Coalesce editor, in an IDE, or with an AI assistant. Coalesce infers columns, data types, and upstream dependencies. Per-Node options such as truncate-before-insert, Pre-SQL, and insert strategy are expressed as inline annotations in the SQL file.
In a typical pipeline you use both V2 and V1 mapping-grid Node Types: V2 on the staging layer, and V1 for persistent Dimensions and Facts. Both versions run in the same Workspace, and Nodes connect with {{ ref() }}.
How to Build With V1 and V2
Follow this pattern when you add Node Types to a pipeline:
- Stage and Work with V2 - Create V2 Node Types for staging transforms. Author the
SELECTin SQL, including CTEs and AI-generated logic, and store each Node as a.sqlfile. - Dimensions and Facts with V1 - Create or keep Dimensions, Facts, and other history-keeping Nodes on V1 mapping-grid types.
- Wire the DAG - Reference upstream staging Nodes from Dimensions and Facts with
{{ ref() }}, the same as any other Node dependency.
How Columns Work in Each Model
V2 derives the column list from your SELECT. Each column’s identity is its name in that projection. If you change a column name in the SQL, deploy applies that as a new column and removes the previous name from the table definition.
V1 maps columns in the grid and keeps a stable column identity across renames. When you rename a column on a V1 Node, deploy can rename the warehouse column and keep the existing data.
That difference is why staging fits V2 and persistent Dimensions and Facts fit V1:
- Staging tables are often truncated and reloaded, so column names can change with the SQL as you iterate.
- Dimensions and Facts usually keep history across runs, so V1’s rename behavior matches how those tables are maintained.
When V2 Fits Your Staging Workflow
On the staging layer, choose V2 when SQL is the natural starting point:
- Migrating SQL into Coalesce - Bring existing SQL, dbt models, or stored procedure logic without splitting it into per-column mappings.
- CTE-heavy logic - Represent CTEs inside a single Node, which the mapping grid does not support.
- AI-generated SQL - Check in full
SELECTstatements from an IDE or AI assistant and keep lineage and governance in Coalesce. - Code-first workflows - Version transformations as plain
.sqlfiles next to the rest of your code.
For visual, low-code modeling on persistent Dimensions and Facts, use the mapping grid.
How V1 and V2 Differ
Use this table to compare authoring and storage. Execution, templates, and pipeline behavior are covered in the next section.
| V1 Node Type | Node Type V2 | |
|---|---|---|
| Authoring | Mapping grid | SQL editor |
| File format | .yml | .sql |
| Column definition | Manually mapped in the grid | Inferred from your SELECT clause; the column list is read-only in the UI |
| Column identity | Stable ID across renames | Name in the SELECT |
| Source dependencies | Selected in the UI | Declared with {{ ref() }} in SQL |
| Per-Node configuration | Config panel on each Node | Inline SQL annotations and Options; see SQL Annotations Reference |
| CTE support | Not available inside a single Node | Supported natively |
| Node Type Specs | Config items in the YAML definition | Config items in the YAML definition declare which annotations the type supports; templates consume them |
| Where to use it | Persistent Dimensions, Facts, and other history-keeping Nodes | Staging and other SQL-first transforms |
You choose the version per Node Type. {{ ref() }} works the same whether the upstream Node is V1 or V2.
Node Types still use a YAML definition plus Create and Run templates. You declare which annotations a type supports in the definition, wire them in templates, then set values in each Node's SQL, or in Options when the definition exposes toggles and fields. See How V2 Annotations Reach Deployed SQL.
The older inputMode: 'sql' setting on V1 Node Type definitions is deprecated and will be removed in a future release. Node Types that use it show a deprecation warning in the Coalesce App. See Upgrading from V1 to V2 Node Types to migrate.
How V2 Annotations Reach Deployed SQL
An annotation in Node SQL does not change warehouse behavior by itself. Work through these layers for every option you want to use, for example @truncateBefore, @preSQL, @insertStrategy, or column flags such as @isBusinessKey:
- Node Type Definition - Declare the option as a config item in the YAML definition so Coalesce registers the annotation, applies defaults, and can show Options controls. Match
attributeNameto the annotation name, for exampletruncateBeforefor@truncateBefore, or any name you define, such asmyLoadModefor@myLoadMode. See Node Config Options and Getting Started with Node Type V2. - Create and Run Templates - Read the hydrated metadata in Jinja, for example
config.truncateBefore,config.preSQL.parameters, orcolumn.isBusinessKey, and emit the matching DDL or load stages. - Node SQL - Set the annotation on the Node, or use Options when the definition exposes the field.
If any layer is missing, the annotation may parse but the compiled plan can omit the stage you expect. That can surface as a successful run with no error, for example insert-only loads when truncate was intended.
What Stays the Same in Your Pipeline
Create, Run, Join, and Macro templates, deployment, execution, DAG and column-level lineage, testing, and governance policies work the same as for other Node Types.
Data Platform Support
Node Type V2 is supported on Snowflake.
What's Next?
- Getting Started with Node Type V2 to create your first V2 Node Type and Node for staging.
- The V2 Editor for a tour of the interface.
- SQL Annotations Reference for syntax, Node Type definition, and template wiring.
- Upgrading from V1 to V2 Node Types if you need to leave deprecated
inputMode: 'sql'. - Troubleshooting and FAQ for parse, column, and annotation issues while authoring V2 SQL.